

Web scraping, web harvesting, web data extraction merupakan kegiatan yang dilakukan untuk mengambil data tertentu secara semi-terstruktur dari sebuah halaman website. Halaman tersebut umumnya dibangun menggunakan bahasa markup seperti HTML atau XHTML, proses akan menganalisis dokumen sebelum memulai mengambil data.
Sederhana nya, web scraping adalah aktivitas untuk mengambil data dari sebuah website, untuk apa? Terserah, bisa untuk ditampilkan ulang di aplikasi kita, membuat dataset untuk training Machine Learning, atau untuk kebutuhan-kebutuhan lain.
Web Scraping sendiri bisa dilakukan baik secara manual maupun otomatis. Manual artinya kita melakukan copy-paste konten pada website secara manual satu per satu, kalau datanya sedikit sih gak masalah ya, tapi akan sangat merepotkan kalau datanya ada banyak sekali. Cara otomatis berarti proses pengambilan data dijalankan secara otomatis oleh komputer sesuai perintah yang kita tulis. Pada artikel ini tentunya kita akan membahas scraping secara otomatis, kalau manual gak perlu dibahas 😬
Pada artikel ini kita akan membahas bagaimana cara melakukan web scraping menggunakan beberapa bahasa pemrograman dengan metode HTML Parsing, yaitu mengambil data berdasarkan Tag/ID/Class HTML.
Contoh, saat kita membuka halaman dengan tampilan seperti dibawah:
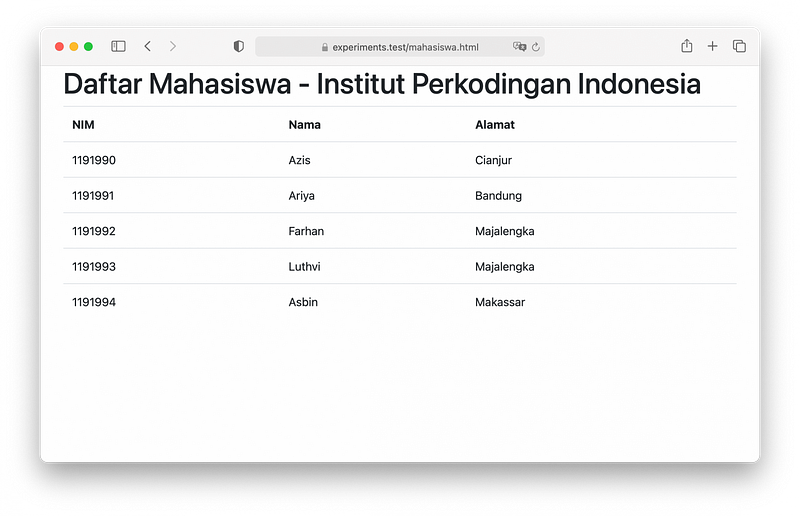
Maka tampilan tersebut sebetulnya adalah kode HTML yang sudah di render oleh browser, dibelakang layar sebetulnya server mengirim respon ke browser dalam bentuk teks HTML seperti ini:
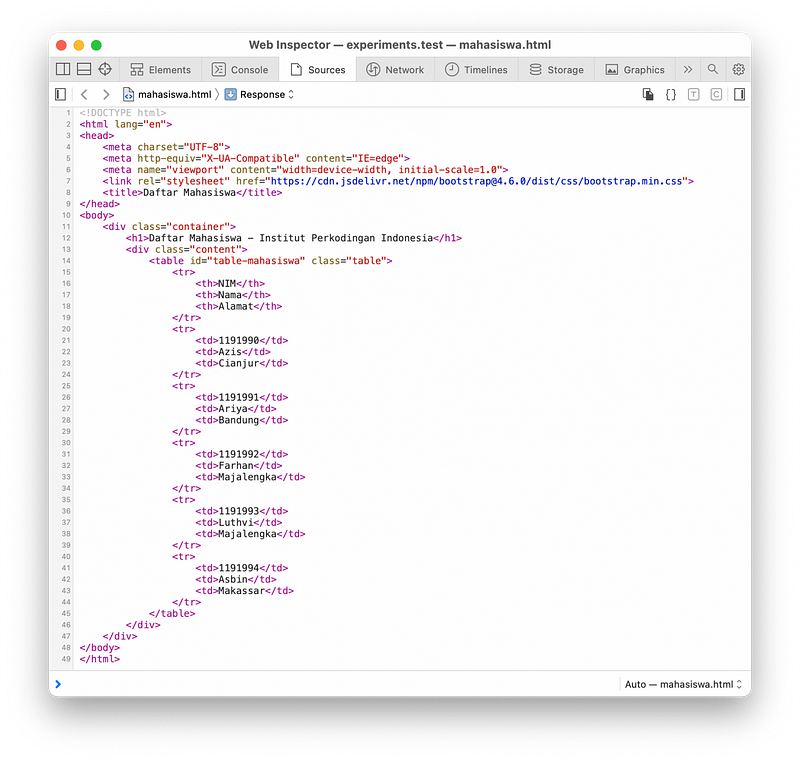
Dari kode HTML diatas, bisa kita simpulkan bahwa data mahasiswa ada di .container > .content > #table-mahasiswa > tr, masing-masing tr berisi 1 data mahasiswa. Kolom ( td) pertama pada tr berisi NIM, kolom ke-2 berisi Nama, dan kolom ke-3 berisi Alamat. Harap diingat juga bahwa tr pertama merupakan judul, jadi jangan dianggap.
Analisis diatas adalah hal yang pertama harus kita lakukan sebelum menulis kode, kalau sudah dapat analisa seperti diatas maka tinggal kita convert ke bahasa pemrograman yang kita inginkan.
Apakah Web Scraping Legal?
Sejauh ini saya belum menemukan aturan yang melarang web scraping, tapi kembali lagi ke Ketentuan Layanan dari website yang akan kita scrape, beberapa website ada yang melarang konten pada website nya untuk di Scrape. Menurut saya pribadi selama tidak menimbulkan kerugian (dalam bentuk apapun, misal: plagiarism, informasi sensitif, dsb.) seharusnya tidak masalah.
Contoh Kode Untuk Web Scraping
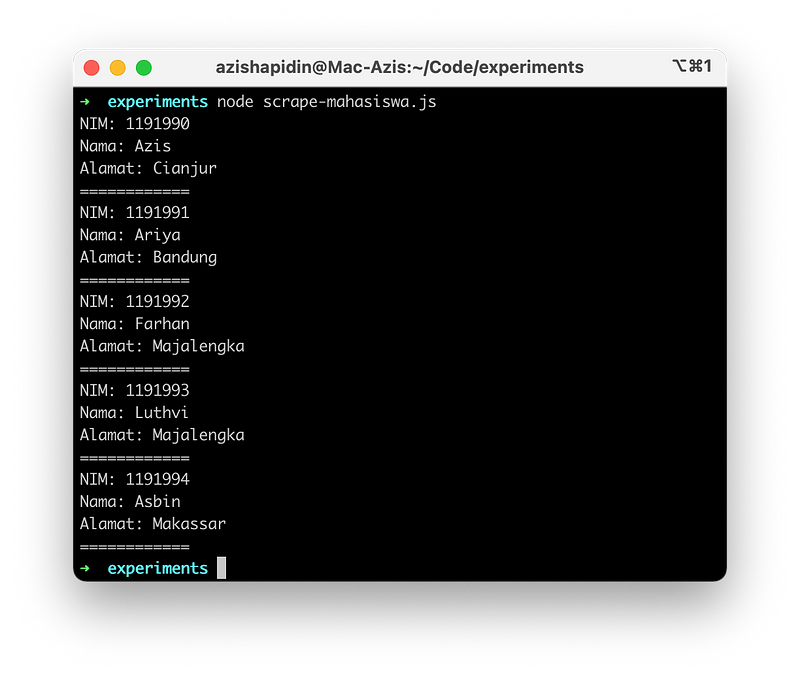
Dibawah ini ada beberapa contoh kode scraping data mahasiswa diatas dalam bahasa pemrograman Python, NodeJS, dan juga PHP.
Python
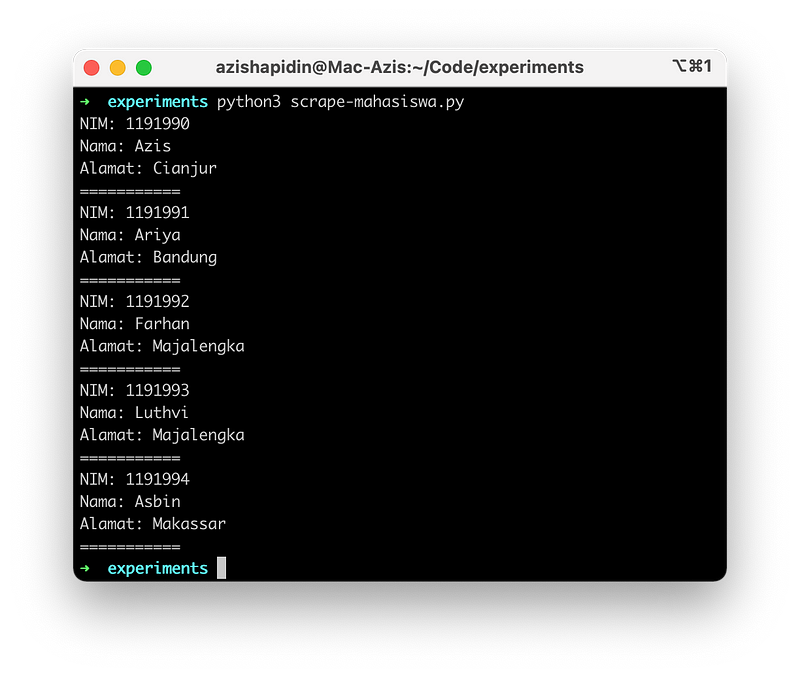
Pada Python kita bisa menggunakan library pihak ketiga Beautiful Soup untuk melakukan parsing HTML, kurang lebih seperti ini:
import requests
from bs4 import BeautifulSoup
page = requests.get('http://experiments.test/mahasiswa.html')
soup = BeautifulSoup(page.content, 'html.parser')
items = soup.find('div', class_='container').find('div', class_='content').find('table', id='table-mahasiswa').find_all('tr')
for item in items:
tds = item.find_all('td')
if len(tds) == 0:
continue
print('NIM: ' + tds[0].text)
print('Nama: ' + tds[1].text)
print('Alamat: ' + tds[2].text)
print('===========')
PHP
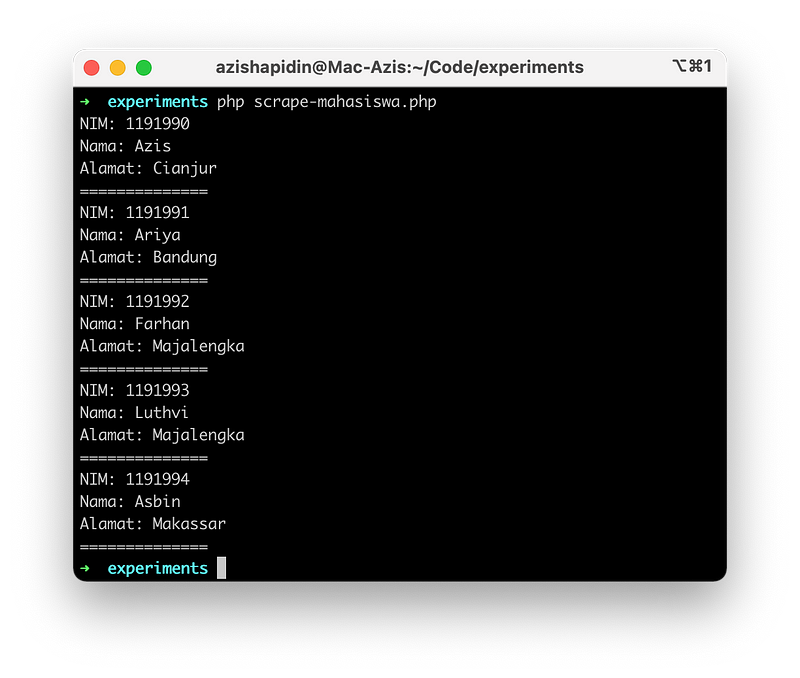
Pada PHP, kita bisa menggunakan library PHP Simple HTML DOM Parser, kita tinggal download lalu panggil library tersebut pada kode PHP kita.
<?php
require 'simple_html_dom.php';
$html = file_get_html('http://experiments.test/mahasiswa.html');
$items = $html->find('.container', 0)->find('.content', 0)->find('#table-mahasiswa', 0)->find('tr');
foreach ($items as $key => $item) {
// Skip first item
if ($key == 0) {
continue;
}
echo 'NIM: ' . $item->find('td', 0)->plaintext . PHP_EOL;
echo 'Nama: ' . $item->find('td', 1)->plaintext . PHP_EOL;
echo 'Alamat: ' . $item->find('td', 2)->plaintext . PHP_EOL;
echo '==============' . PHP_EOL;
}
NodeJS
Salah satu tools yang biasa saya gunakan untuk parsing HTML di NodeJS adalah cheerio yang bisa kita install lewat npm.
var cheerio = require('cheerio');
const request = require('request');
request('http://experiments.test/mahasiswa.html', function (error, response, html) {
var $ = cheerio.load(html);
$('.container .content #table-mahasiswa tr').each(function(key, element){
// Skip first item
if (key === 0) {
return true;
}
var tr = $(element);
console.log('NIM: ' + tr.children().eq(0).text());
console.log('Nama: ' + tr.children().eq(1).text());
console.log('Alamat: ' + tr.children().eq(2).text());
console.log('============')
});
});
Tips Agar Website Kita Tidak Mudah di-Scrape
Salah satu goal kita sebagai developer mempelajari Web Scraping adalah kita bisa ‘meminimalisir’ aplikasi web kita untuk bisa dengan mudah di scrape oleh orang lain. Kenapa perlu di minimalisir? Selain ada kemungkinan data/informasi sensitif yang bisa bocor, scraping yang dilakukan secara besar-besaran dan terus menerus juga bisa menambah beban server aplikasi kita.
- Jangan tampilkan data sensitif secara publik. Tampilkan data sensitif hanya untuk user yang sudah login.
- Menggunakan Captcha. Ini sebabnya kenapa kita sering melihat Captcha pada halaman Register/Login, yaitu untuk mempersulit robot Scraper.
- Menggunakan CSRF Token. CSRF Token adalah metode untuk memastikan bahwa request berasal dari dalam aplikasi (bukan dari luar), yaitu dengan cara mengirimkan token saat request, jika token tidak valid maka request tidak akan bisa diproses. Token memiliki masa kadaluwarsa dan hanya bisa digunakan untuk 1 kali request saja.
- Rate Limit Request. Ini akan sangat berguna jika data yang akan di scrape adalah data dari banyak url sekaligus, kita bisa menambahkan Rate Limit Request pada aplikasi web server kita (misal: NGINX atau Apache).
- Modifikasi HTML dalam interval waktu tertentu. Kita bisa mengganti struktur HTML pada aplikasi kita dalam interval waktu tertentu, termasuk juga Class dan ID pada HTML.
- Jangan gunakan ID Increment sebagai parameter di URL. Salah satu kesalahan dalam menentukan URL adalah menggunakan ID Increment sebagai parameter, misal:
https://kampus-keren.com/detail-mahasiswa/1,https://kampus-keren.com/detail-mahasiswa/2, sampaihttps://kampus-keren.com/detail-mahasiswa/10000. Dengan menggunakan cara seperti ini berarti kita memberi karpet merah kepada Scraper untuk mengambil data pada website kita, Scraper tinggal bikin looping saja dari 1-10rb. Dibanding menggunakan ID Increment, kita bisa menggunakan Slug, UUID, atau bisa juga Hashed ID.
Sekian tulisan mengenai Web Scraping ini, jika punya pendapat lain ditunggu di kolom komentar.
Terima kasih! 😎







{kind=link}